-
그래프(graph)의 구현 2가지Computer Science/Data_Structure 2020. 1. 4. 06:05728x90반응형
그래프를 구현하는 방법은 책을 보거나, 구글링을 해보아도 전부 인접행렬 or 인접리스트를 이용하여 구현을 한다.
상황에 맞게 시간복잡도를 고려하여 더 효율적인 것을 사용하면 된다. 그래서 각각의 장단점을 공부하려 글을 쓰려 한다.
https://kosaf04pyh.tistory.com/131
[자료구조] 그래프(Graph)
이번시간에는 그래프에 대해 공부해 보겠습니다. 그래프란 ? 그래프는 정점(Vertex)간의 관계를 표현하는 자료구조 입니다. 그래프 G = (V,E)로 정의하는데, V(Vertex)는 그래프에 있는 정점들의 집합을 의미하고..
kosaf04pyh.tistory.com
https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html
[자료구조] 그래프(Graph)란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
(위에서 공부한 내용을 정리하고 있습니다. ) (참고자료 입니다)
1. 인접리스트(Adjacency List)
인접 리스트(Adjacency List)로 그래프를 구현하는 것이 가장 일반적이다.
- 모든 정점을 인접 리스트에 저장한다. 각 정점에 인접한 정점들을 리스트로 표현
- 배열과 동적 가변 크기 배열(ArrayList), 연결리스트(LinkedLIst)를 이용해서 인접리스트를 표현
- 정점의 번호만 알면 번호를 배열의 인덱스로 하여 각 정점의 리스트에 쉽게 접근 가능
- 트리 구조라면 루트노드에서 다른 노드 한번에 접근 가능(사이클도 없고, 트리 구조 이기 때문)
- 그래프라면 루트노드에서 한번에 접근이 불가능 함
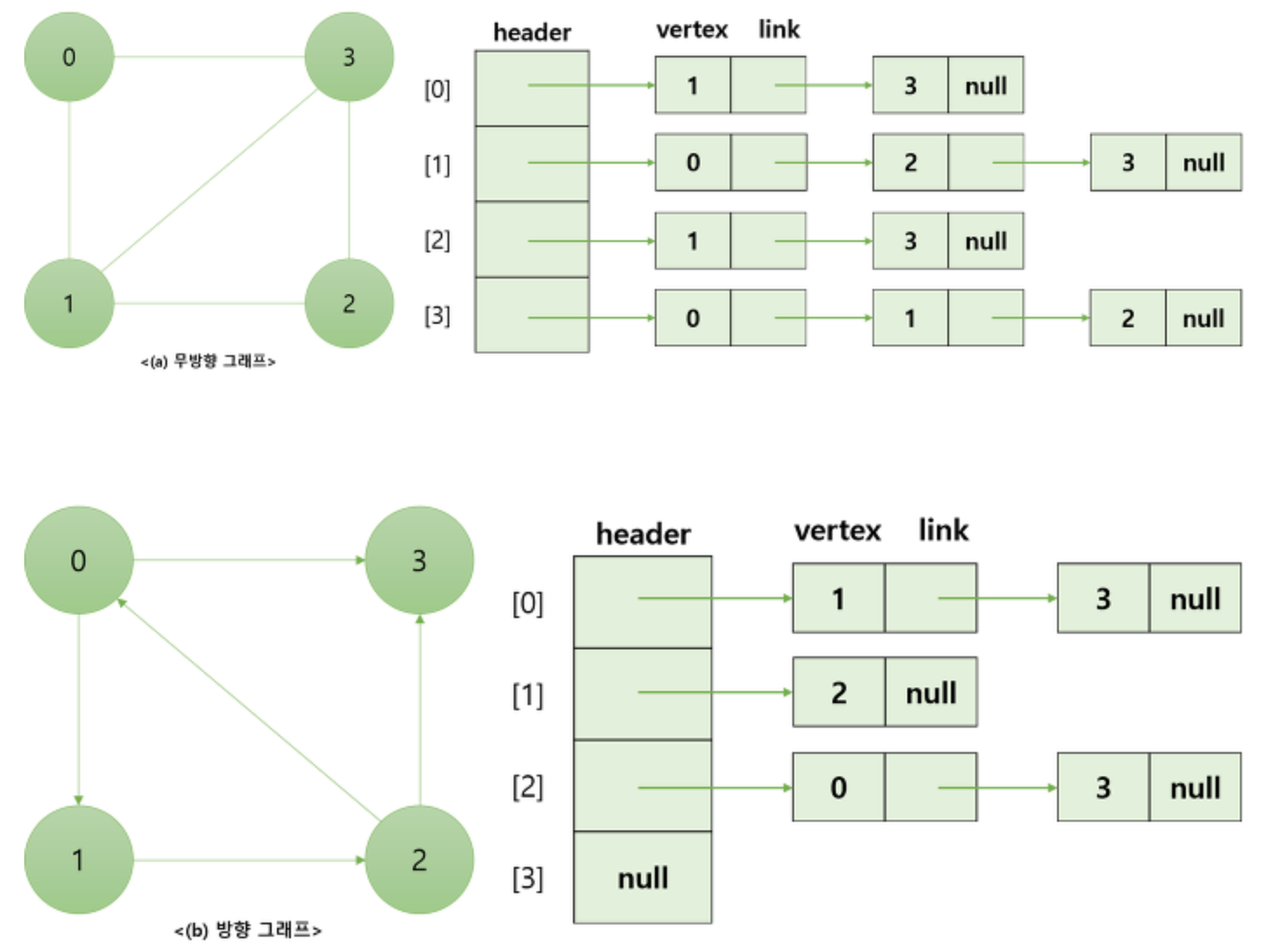
출처 : https://kingpodo.tistory.com/46 위의 그림에서 리스트를 보면 header에 연결되어 있는 노드들의 순서는 의미가 없고, 보기 좋게 오름차순으로 나타낸 것이다.
2. 인접행렬(Adjacency Matrix)
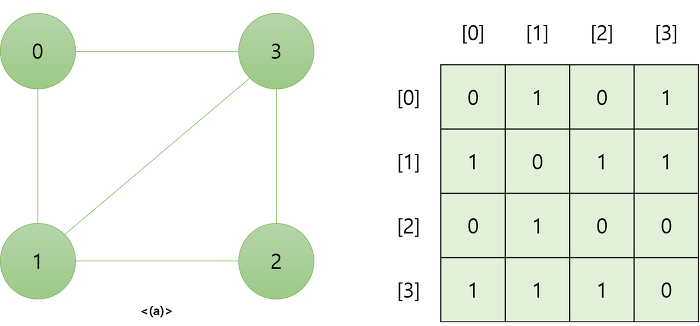
인접 행렬은 NxN 불린 행렬(Boolean Matrix)로써 matrix[i][j]가 true라면 i -> j로의 간선이 있다는 뜻이다.
- 정점의 개수가 N인 그래프를 인접행렬로 표현하면 N*N개의 메모리 공간이 필요함
- 인접 행렬은 간선이 적은 희소 그래프인 경우에는 인접 행렬이 희소 행렬이 되므로 메모리 낭비 문제가 발생함
- 전체노드의 개수를 V가, 간선의 개수를 E개라고 가정하자. 그리고 노드 i에 연결된 모든 노드를 방문하고 싶을 때 adj[i][1] 부터 adj[i][v] 까지 모두 확인해봐야 하기 때문에 총 O(V)의 시간이 걸리게 된다.
출처 : https://kingpodo.tistory.com/46 인접리스트와 인접행렬 선택방법
인접 리스트
그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프의 경우 사용
장점
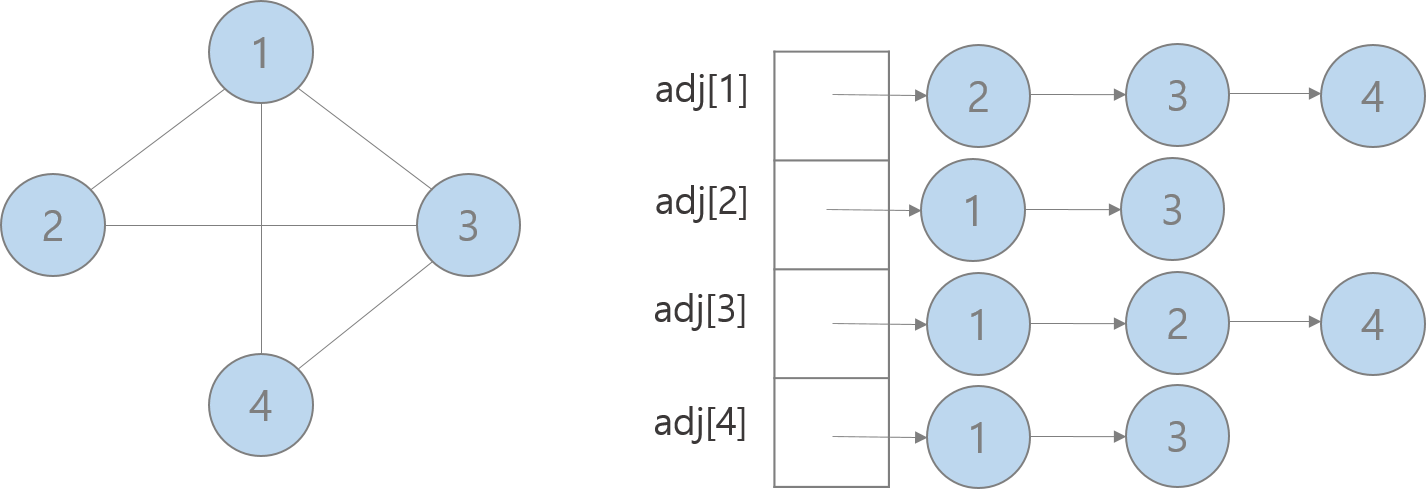
- 인접 리스트는 실제로 연결된 노드들에 대한 정보만 저장하기 때문에, 그래프의 간선의 개수와 리스트의 원소의 개수가 같다는 점이 있다(중복된 부분 제외) 한마디로 간선의 개수에 비례하는 메모리만 차지한다는 것을 알 수 있다.
- 예를들어 인접행렬의 경우 2번 리스트를 보면 adj[2][1], adj[2][2], adj[2][3], adj[2][4] 처럼 4번을 확인해야 하지만, 인접리스트의 경우 2번 리스트의 Size만큼만 확인해보면 된다는 장점이 있다.
- 인접리스트의 경우에는, 각노드마다 연결된 노드만 확인하는 것이 가능하다. 따라서 전체 간선의 개수만큼만 확인해볼 수 있다. 따라서 E가 간선의 개수라면, O(E)의 시간 복잡도를 가진다고 할 수 있다. 따라서 이렇게 모든 노드들을 방문해 보아야 하는 경우, 인접리스트를 이용하는 것이 시간상의 장점을 가진다고 할 수 있다.
단점
- 노드 i와 j가 연결되어 있는지 알고 싶다면 인접행렬의 경우 adj[i][j]가 1인지 0인지 유무를 판단해서 O(1)에 확인할 수 있지만 인접리스트의 경우는 리스트의 간선을 확인해봐야 하기 때문에 시간복잡도는 O(V)가 된다.
인접행렬
그래프에 간선이 많이 존재하는 밀집 그래프의 경우
장점
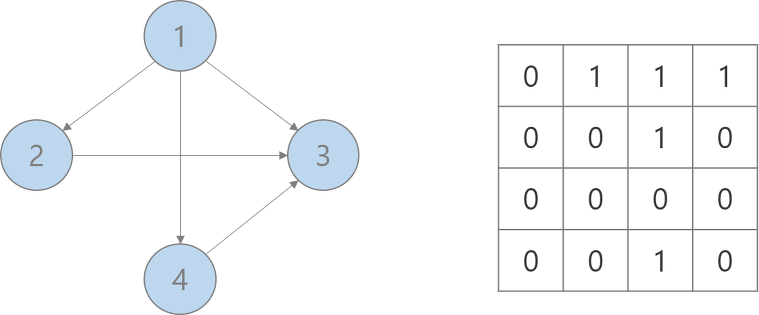
- 두 정점을 연결하는 간선의 존재 여부를 O(1)안에 즉시 알 수 있음 (adj[i][j]가 1인지 0인지 확인하면 됨)
- 정점의 차수는 O(N)안에 알 수 있다.
단점
- 어떤 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 전부 순회해야 함 => 정점의 개수가 매우 많고 간선의 개수는 정점당 2개정도 밖에 안된다고 가정하면 연결된 간선을 찾기 위해서 모든 정점을 순회해야 하는 단점을 가지고 있다.
- 그래프에 존재하는 모든 간선의 수는 O(N*N)안에 알 수 있다.
뭐 일단은 간선의 수가 많으면 인접행렬이 효율적이고, 간선의 수가 적다면 인접리스트가 효율적이라는 뜻이겠지..
Reference
https://sarah950716.tistory.com/12
[그래프] 인접 행렬과 인접 리스트
그래프 관련 문제를 풀 때는, 문제 상황을 그래프로 모델링한 후에 푸는 것이 보편적입니다. 이 때, 모델링한 그래프의 연결관계를 나타내는 두 가지 방식이 있습니다. 1. 인접 행렬 2. 인접 리스�
sarah950716.tistory.com
반응형'Computer Science > Data_Structure' 카테고리의 다른 글
선택 정렬(selection sort) 란? (0) 2020.01.07 해싱(Hashing) 이란? (0) 2020.01.04 너비 우선 탐색(BFS) 란? (0) 2020.01.04 깊이 우선 탐색(DFS) 란? (0) 2020.01.04 그래프(Graph) 란? (0) 2020.01.03